相关工作
乍一看,Triton 可能只是另一种用于深度神经网络 (DNNs) 的领域特定语言 (DSL)。本节旨在将 Triton 置于上下文中,并突出其与该领域的两种主要方法即多面体编译和调度语言的区别。
多面体编译
传统编译器通常依赖于中间表征 (intermediate representations),如 LLVM-IR [LATTNER2004],它使用(无)条件分支来编码控制流信息。这种相对低阶的格式在静态分析输入程序的运行时行为(例如缓存未命中),通过使用平铺 [WOLFE1989]、融合 [DARTE1999] 和交换 [ALLEN1984] 等技术自动优化循环中更为困难。为了解决这个问题,多面体编译器 [ANCOURT1991] 依赖于具有静态可预测控制流的程序表示,从而可以进行针对数据局部性和并行性的激进编译时程序转换。尽管这种策略已被许多用于 DNNs 的语言和编译器采用,如 Tiramisu [BAGHDADI2021]、Tensor Comprehensions [VASILACHE2018]、Diesel [ELANGO2018] 和 MLIR 中的 Affine 方言 [LATTNER2019],但它也存在一些限制,稍后本节将进行描述。
程序表征
多面体编译是一个广泛的研究领域。在本节中,我们仅概述了这个主题的基础概念,对其背后的线性和整数编程感兴趣的读者,可参考更多相关文献。
for(int i = 0; i < 3; i++)
for(int j = i; j < 5; j++)
A[i][j] = 0;
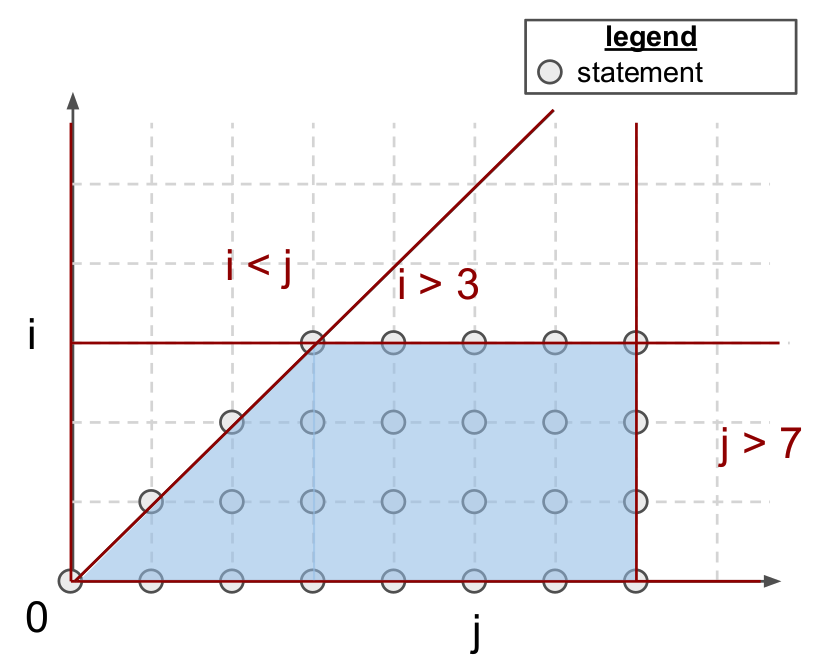
多面体编译器专注于一类程序,通常称为静态控制部分 (SCoP) ,即包含条件语句和循环边界为环绕循环索引和全局不变参数的仿射函数的最大连续语句集合。如上所示,这种格式的程序始终导致由仿射不等式界定的迭代域,即多面体。这些多面体也可以通过代数方式定义;对于上述示例:
每个点 (i, j) 在 中代表一个多面体语句,即一个程序语句, (1) 不引起控制流副作用(例如 for、if、break), (2) 仅包含循环索引和数组访问中的仿射函数的全局参数。为了便于别名分析,数组访问还被数学抽象化,使用所谓的访问函数。换句话说,A[i] [j] 只是 A[f(i,j)],其中访问函数 f 定义为:
注意,SCoP 的迭代域不指定其语句执行的顺序。事实上,这个迭代域可以以许多不同的合法顺序进行遍历,即调度。形式上,调度被定义为 p 维仿射变换 ,其循环索引 和全局不变参数 :
其中 是一个 p 维向量,表示在遍历 S 周围的循环嵌套时,从最慢增长到最快增长的索引(从左到右)。对于上述代码,通过使用 C 中循环嵌套定义的原始调度可以检索到:
\Theta_S(\mathbf{x}) = \begin{pmatrix}1 & 0 \0 & 1 \\end{pmatrix}\begin{pmatrix}i & j\end{pmatrix}^T=^T
其中 i 和 j 分别是嵌套中最慢和最快增长的循环索引。如果 T_S 是一个向量(或张量),那么 被称为一维(或多维)。
优势
适合多面体编译的程序可以进行激进的转换和优化。这些大多数转换实际上归结为生成能够促进并行性和空间/时间数据局部性的调度和迭代域(例如融合、交换、平铺、并行化)。
多面体编译器还可以自动通过复杂的验证过程来确保其输入程序的语义在优化阶段保持不变。请注意,多面体优化器并不与更标准的优化技术不兼容。事实上,这些系统通常被实现为一组可以在传统编译技术之前运行的 LLVM 通道 [GROSSER2012]。
总之,多面体机制在适用时非常强大。已经证明支持大多数常见的循环转换,并且实际上已经实现了与用于稠密矩阵乘法的最先进 GPU 库相媲美的性能 [ELANGO2018]。此外,它也是完全自动的,不需要程序员除了在 C 类似格式的源代码外提供任何提示。
局限性
多面体编译器存在两个主要局限性。这些局限性使得它无法被采纳为神经网络代码生成的普遍方法。
首先,可能的程序转换集合 很大,并随着程序中语句数量以及它们迭代域的大小而增长。验证每个转换的合法性可能需要解决复杂的整数线性规划问题,这使得多面体编译非常计算密集。更糟糕的是,硬件属性(如缓存大小、SM 数量)和上下文特征(如输入张量 shape)也必须被此框架考虑,导致昂贵的自动调优过程[SATO2019]。
其次,多面体框架的适用性不是很广泛;静态控制流图 (SCoPs) 相对常见[GIRBAL2006],但要求循环边界和数组下标是循环索引的仿射函数,这通常仅在正则、密集计算中发生。因此,该框架仍需成功应用于稀疏甚至结构稀疏的神经网络,这些网络在过去几年中越来越重要。
另一方面,本文推荐的基于块的程序表征在范围上不那么受限,可以通过标准数据流分析实现接近峰值性能。
调度语言
分离关注点 (Separation of concerns) [DIJKSTRA82] 是计算机科学中一个众所周知的设计原则:程序应该被分解成模块化的抽象层次,将算法的语义与实现的细节分离开。像 Halide 和 TVM 这样的系统更进一步,通过使用调度语言在语法级别强制执行此分离。这种方法的好处在矩阵乘法的情况下特别明显,如下所示,算法的定义(第 1-7 行)与其实现(第 8-16 行)完全不同,这意味着两者可以独立维护、优化和分发。
// algorithm
Var x("x"), y("y");
Func matmul("matmul");
RDom k(0, matrix_size);
RVar ki;
matmul(x, y) = 0.0f;
matmul(x, y) += A(k, y) * B(x, k);
// schedule
Var xi("xi"), xo("xo"), yo("yo"), yi("yo"), yii("yii"), xii("xii");
matmul.vectorize(x, 8);
matmul.update(0)
.split(x, x, xi, block_size).split(xi, xi, xii, 8)
.split(y, y, yi, block_size).split(yi, yi, yii, 4)
.split(k, k, ki, block_size)
.reorder(xii, yii, xi, ki, yi, k, x, y)
.parallel(y).vectorize(xii).unroll(xi).unroll(yii);
然而,生成的代码可能并非完全可移植,因为调度有时可能依赖于执行模型(例如 SPMD )或硬件指令(例如矩阵乘累加),这些在广泛可用性方面并不普遍。自动调度机制 [MULLAPUDI2016] 可以缓解这个问题。
优势
这种方法的主要优势在于,它允许程序员仅编写一次算法,并专注于性能优化。可以手动指定优化,而多面体编译器无法通过静态数据流分析自动找出这些优化方法。
调度语言无疑是神经网络代码生成中最受欢迎的方法之一。这一目标中最流行的系统可能是 TVM,它在广泛的平台上提供良好的性能以及内置的自动调度机制。
局限性
这种开发的便利性是有代价的。首先,遵循这一范例的现有系统在适用时(例如 V100/A100 张量核心与相等块大小)通常比 Triton 在现代硬件上慢得多。我相信这不是调度语言的根本问题——在某种程度上,可能可以通过更多的努力解决——但这可能意味着这些系统更难工程化。更重要的是,现有的调度语言生成的循环其界限和增量不能依赖于周围循环索引,至少对可能的调度施加严格约束,甚至可能会破坏系统。这对于稀疏计算尤其成问题,其迭代空间可能是不规则的。
for(int i = 0; i < 4; i++)
for(int j = 0; j < 4; j++)
float acc = 0;
for(int k = 0; k < K[i]; k++)
acc += A[i][col[i, k]] * B[k][j]
C[i][j] = acc;
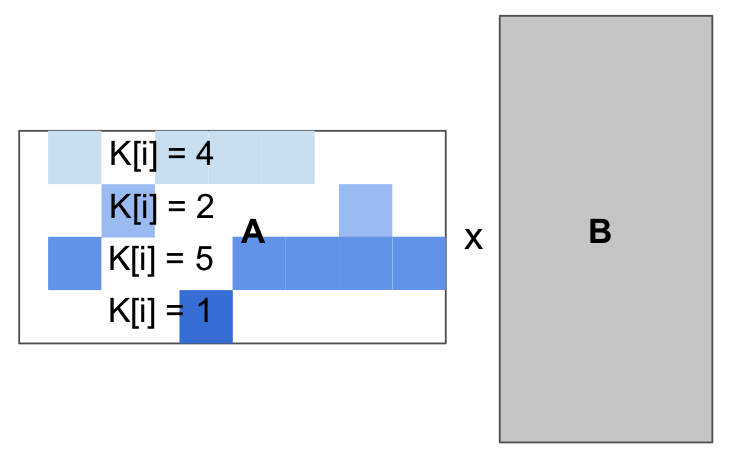
另一方面,我们通过本文推荐的基于块的程序表示允许块结构化的迭代空间,并允许程序员根据需要手动处理负载平衡。
References 参考文献
Lattner et al., "LLVM: a compilation framework for lifelong program analysis transformation", CGO 2004
Wolfe, "More Iteration Space Tiling", SC 1989
Darte, "On the Complexity of Loop Fusion", PACT 1999
Allen et al., "Automatic Loop Interchange", SIGPLAN Notices 1984
Ancourt et al., "Scanning Polyhedra with DO Loops", PPoPP 1991
Baghdadi et al., "Tiramisu: A Polyhedral Compiler for Expressing Fast and Portable Code", CGO 2021
Vasilache et al., "Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions", ArXiV 2018
Elango et al. "Diesel: DSL for Linear Algebra and Neural Net Computations on GPUs", MAPL 2018
Lattner et al., "MLIR Primer: A Compiler Infrastructure for the End of Moore’s Law", Arxiv 2019
Grosser et al., "Polly - Performing Polyhedral Optimizations on a Low-Level Intermediate Representation", Parallel Processing Letters 2012
Sato et al., "An Autotuning Framework for Scalable Execution of Tiled Code via Iterative Polyhedral Compilation", TACO 2019
Girbal et al., "Semi-Automatic Composition of Loop Transformations for Deep Parallelism and Memory Hierarchies", International Journal of Parallel Programming 2006
Dijkstra et al., "On the role of scientific thought", Selected writings on computing: a personal perspective 1982
Mullapudi et al., "Automatically scheduling halide image processing pipelines", TOG 2016